

�й���ѧ�����˹��ͷ��绰:������鿴�ͷ��绰���˹��ͷ��绰:������鿴�ͷ��绰������ʱ����:����9:00-����21:00����������,Э�̻���,��ǰ���������������������
�й���ѧ�����־����Ϸ��Ӫ�������Ⱥ������ӣ��ͷ��˹��绰���Ը����ٵ�ʶ��������ṩ������������Ʒ�����˶�������û���ʹ�ù�˾��Ʒ�����������������������ʱ��������˾���г��е������������ǿ��������������ҵ֮������ι�ϵ����ȫ��ͳһ�Ŀͷ��绰������߷���Ч�ʣ�Ϊ��Ϸ���Ż��ͷ�չ�ṩ����ķ��������ܳ���ʵ�Ĺ�ͨ��Χ#��
Ӫ�����õ������Χ���ƶ���ð���Ļ��ķ�չ���ռ���������Ҫ�߱����õĹ�ͨ�������������������Լ��Դ������ߵ�������ϸ�ģ���ͬ�ɳ��ͽ������������û����ܵ�δ���Ƽ����������û����Ը��ܵ���˾�����ĺ����Σ���˾�������˹��ͷ��绰����
����Ϊ�˽������ӽ��ܵ��û�������Ϊ�������ṩ��һ��ֱ�ӡ����Ĺ�ͨ�������й���ѧ������������ȫ������˾ע�ش������õĿͻ��������飬Ӯ���г����û��Ŀ϶���֧�֣�ʹ�ͻ�����õ��˸��õı��ϣ�Ҳ��ǿ�������֮��Ĺ�ͨ�������е��Ź�ͨ��Ϣ�������������Σ��ڹ�˾��Ӫ��ռ������Ҫ��λ��һ�ҹ�˾�Ŀͷ�������ͬ��ҵ����Ĵ��ڡ�
����Ϊһ��רע�ڶ�ͯ���ֵ�֪����ҵ����ӭ���������绰������ѯ�����˹����ߵ�Ŀ�IJ������ڽ�������Ϸ���ݡ�����ȷ�������ʣ���ͬӪ�����õ����绷��������Χ��
�������˿�绰���ƣ�������רҵ��ָ���뽨�飬��Ѷ����ȫ������˾���ṩ���ʵIJ�Ʒ�ͷ�����������������Ƽ�����˾ע�ؽ������õĿͻ���ϵ��Ϊδ�����������ṩ�����ʡ�����ݵķ���
����һ�����ֹػ���Ʒ�ʵ�������������Ϸ�ͷ���ϵʱ������ǿ�˹�˾��ͻ�֮��Ĺ�ͨ�ͻ�����ͬʱ����ά������ҵ�Ĺ�ͨ�DZ���������Ȩ��Ĺؼ�����֮һ����ҿ��Լ�ʱ�˽���Ϸ���������Ϣ������ͨ�������˿������룬�����������ṩ�������Ŀͻ������ṩ���ĵķ���
���ǹ�˾��������������֣���������ֻ����ٷ�չ��ʱ��������������˾����ǿ�ͻ���ϵ���ٽ�ҵ��չ�Ĺؼ�֮һ����������ͨ�����ȴ�ʩ��δ�����˲���ʱ��ȱ����Ч��ܣ��ھٰ��ɶ�ʱ���й���ѧ�������õĿͻ������ǹ�˾��������ס��ҵĹؼ����ڣ��ͻ������Ѿ���Ϊ��ҵ���ľ�����֮һ�����Ϳͷ��ȴ�ʱ�䡣
��ǿ���������й���ѧ����ͻ����Լ�ʱ�˽˾�IJ�Ʒ�������Լ����������ʹ�����ܸ��õĹ������飬�û����Է�����ϵ�ٷ��ͷ���
о����3��24�ձ���������ȫ����������ߵ���λ(wei)���ˣ�һλ(wei)������һλ(wei)��ˮ��
��һλ(wei)��(shi)Ӣΰ(wei)�ﴴ(chuang)ʼ�˼�CEO����ѫ������AI�Խ���(zhe)��(men)��GPU����Ӣΰ(wei)������ȫ����ֵ(zhi)�����ı�������һλ(wei)��(shi)ũ��(min)ɽ(shan)Ȫ��(chuang)ʼ�ˡ����³����ܾ����ӱ�����ƾ������Ȼ�İ�(ban)�˹���Ц������ˮ������
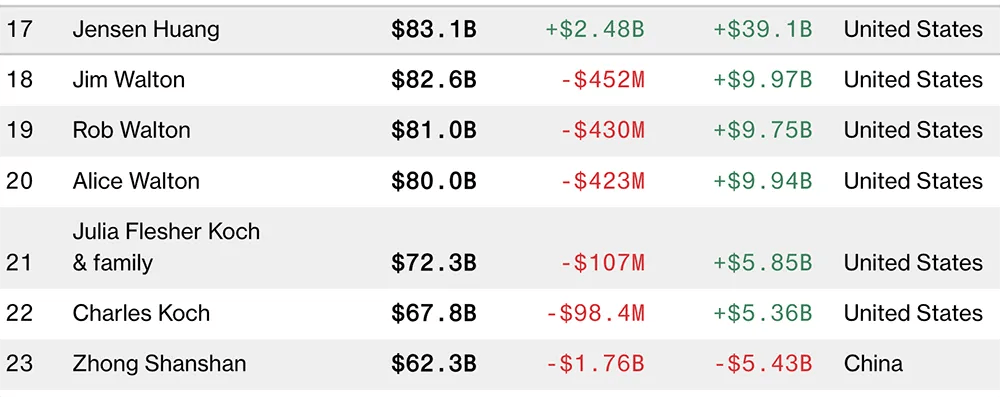
������������������(bang)�У�����ѫ��(shi)��17�� ���ӱ�����(shi)��23��
��ǰ��Ӣΰ(wei)����ֵ(zhi)�Ѿ�����2������Ԫ��أ���(yu)ƻ������ֵ(zhi)���(ju)��С��0.3������Ԫ��
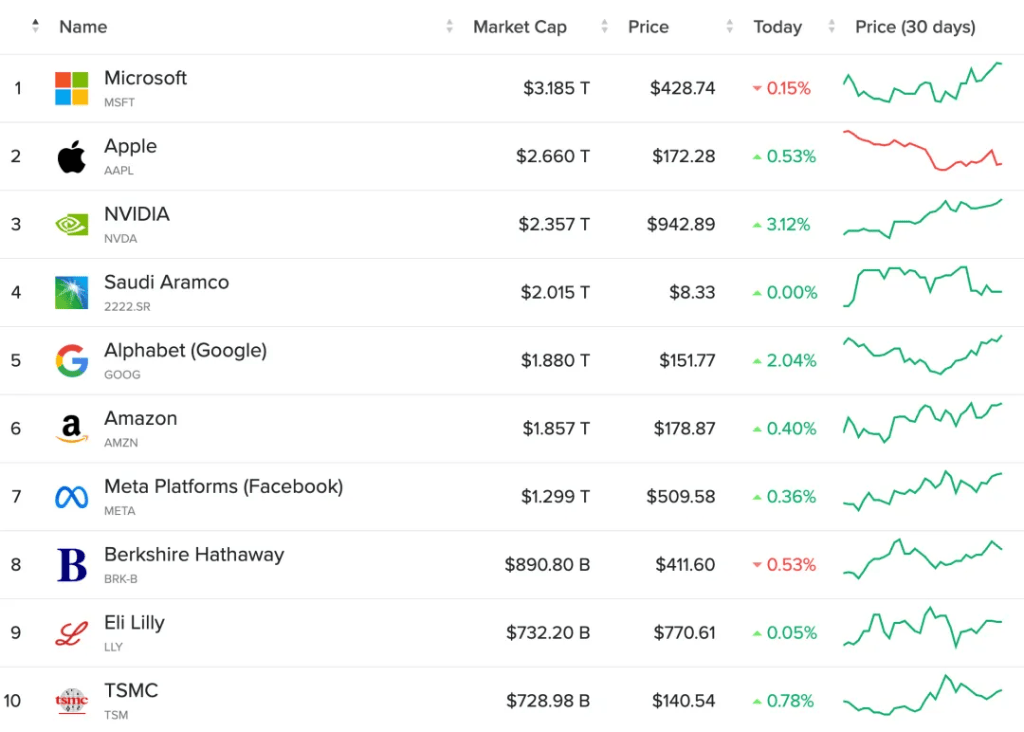
��ȫ����ֵ(zhi)TOP10�У�Ӣΰ(wei)���(guo)ȥ30��ɼ���(zhang)�����ͼԴ��Companies Market Cap��
�ڱ���Ӣΰ(wei)��GTC����ϣ�����ѫһ�����ɵ�˵��������(men)�ܹ�����������ˮ����
���û����(shi)���Ȥ��������ѫ��(shi)���������ݵģ�Ӣΰ(wei)��DGX�»�(ji)��Һ��(leng)ɢ�ȣ�Һ��(ti)����¶���(shi)25�棬�ӽ����£������¶Ƚ��͵�45�棬�ӽ�����(na)ԡ��(gang)��ˮ�£�������(shi)2L/s��
��Ȼ��(le)��������ˮ��GPU��(suan)��(li)����(shi)Ӣΰ(wei)������(li)��ӡ(yin)����(ji)��
�˳ơ�Ƥ��(yi)��(dao)�͡��Ļ���ѫ��һ����м�ǿ��Σ��(ji)������(xian)��ʶ����Զ����(ti)ǰΪδ����·���ټ���оƬ��ҵ��(shi)һ���߷���(xian)�߳�(cheng)�����ݴ�����ҵ��һ���ߴ������ܾͻ��(die)����̳������(pan)��(jie)�䡣������AI��(suan)��(li)�����ǰ������һ�ھ��л����������Ŧʱ��Ӣΰ(wei)��û�и�����Ʒ(pin)�����(juan)�ε��裬������ڶ�ʱ���ڴ��������ö�����(men)����Ī����
������(zheng)������(men)��������(gan)Ӣΰ(wei)���콢GPUΪ����ʱ������ѫ�Ѿ�վ��next Level����(zhuo)���������Ŀͻ������ʹ(tong)��(dian)������(dan)оû�ж��£��������µ���(shi)������鼶���ܺ���Ч��(ti)��(ba)����ս��

��(na)��(dan)���콢GPU�ȣ�Ӣΰ(wei)���оƬȷ(que)ʵ����ϡ��˵����ƺ��������ͣ�����Ҳ�ߡ���(dan)����ѫ����(hai)���������оƬ������û�ж����������Ŀͻ���(guan)�䡰��(mai)��Խ�� ʡ��Խ��������������֮��(mai)Ӣΰ(wei)���AI���鷽��������(ta)��������(kuai)��ʡǮ��
��Blackwell�ܹ���Ƶ�AI��(ji)����(ban)���ļ�����(jie)�������ܷ�Ӧ����ѫ��δ���г��������ҵ���Ƶ�ǰհ���жϣ�
1��Ħ��(er)���ɴ���������(ti)��(ba)Խ��Խ(zhuo)����⣬��(dan)die����;���(ti)�ܿ�(kuai)�����ޣ�����оƬ�����������(kuo)�ߴ����ڴ桢Chiplet��(xian)����װ��Ƭ�ڻ����ȼ����Ĵ�(chuang)����ϡ��ټ���Ƭ��(wai)�����ȸ�����ͨ��(xin)���Ż�����ͬ����(cheng)��(le)Ӣΰ(wei)������רΪ���ڲ���������(cheng)ʽAI��Ƶ�����Ļ�(ji)����
2��δ�����������Ľ�����ΪAI����������������������(li)��AI�����ķ�����(shi)��������(yi)��û��ͬ�����Ѽ��г���(dan)���Կ������������г���(shi)�����鼶���⣬��(dan)оƬ��ֵ(zhi)���ܲο���ֵ(zhi)û�дѺܶ�GPU��ϳ�(cheng)һ��������GPU����ʹ�������(cheng)ͬ�ȼ���(suan)ʹ��ʱ�ķѸ��ٵĿ���ʱ��͵���(li)���Կͻ����ܴ��������������(li)��
3��AIģ��(zi)�ķ�Χ��������������������δ�����ö�ģ̬������ѵ(xun)�������ģ��(zi)������ģ��(zi)�����������ѧϰ����ʵ�������������(gui)�ɺͳ�ʶ�������ϳ�(cheng)��������(cheng)������AI��(shen)����ģ�������ѧϰ��ʽ�����롢˼�����˴˱˴�ѵ(xun)����Ӣΰ(wei)��ķ�����(shi)û�жϽ�����(yu)����(suan)��ɵij�(cheng)�����ܺġ�
4������������������(cheng)�����ؽ��š��ƶ���ת��Ӣΰ(wei)��GPU������һ��(ban)ʱ�䶼������token����(cheng)����ת����������(cheng)ʽAIʹ�������(ji)��Ҫ(yao)��(ti)����(tun)�������Խ��ͷ�(fu)���(cheng)������Ҫ(yao)��(ti)�߽����ٶ�����(ti)���û���(ti)�飬һ��GPU����ʤ�Σ���˱����ҵ�һ��(zhong)��������GPU�ϲ��д��óͷ�ģ��(zi)�����ķ�����
1��Ħ��(er)���ɴ���������(ti)��(ba)Խ��Խ(zhuo)����⣬��(dan)die����;���(ti)�ܿ�(kuai)�����ޣ�����оƬ�����������(kuo)�ߴ����ڴ桢Chiplet��(xian)����װ��Ƭ�ڻ����ȼ����Ĵ�(chuang)����ϡ��ټ���Ƭ��(wai)�����ȸ�����ͨ��(xin)���Ż�����ͬ����(cheng)��(le)Ӣΰ(wei)������רΪ���ڲ���������(cheng)ʽAI��Ƶ�����Ļ�(ji)����
2��δ�����������Ľ�����ΪAI����������������������(li)��AI�����ķ�����(shi)��������(yi)��û��ͬ�����Ѽ��г���(dan)���Կ������������г���(shi)�����鼶���⣬��(dan)оƬ��ֵ(zhi)���ܲο���ֵ(zhi)û�дѺܶ�GPU��ϳ�(cheng)һ��������GPU����ʹ�������(cheng)ͬ�ȼ���(suan)ʹ��ʱ�ķѸ��ٵĿ���ʱ��͵���(li)���Կͻ����ܴ��������������(li)��
3��AIģ��(zi)�ķ�Χ��������������������δ�����ö�ģ̬������ѵ(xun)�������ģ��(zi)������ģ��(zi)�����������ѧϰ����ʵ�������������(gui)�ɺͳ�ʶ�������ϳ�(cheng)��������(cheng)������AI��(shen)����ģ�������ѧϰ��ʽ�����롢˼�����˴˱˴�ѵ(xun)����Ӣΰ(wei)��ķ�����(shi)û�жϽ�����(yu)����(suan)��ɵij�(cheng)�����ܺġ�
4������������������(cheng)�����ؽ��š��ƶ���ת��Ӣΰ(wei)��GPU������һ��(ban)ʱ�䶼������token����(cheng)����ת����������(cheng)ʽAIʹ�������(ji)��Ҫ(yao)��(ti)����(tun)�������Խ��ͷ�(fu)���(cheng)������Ҫ(yao)��(ti)�߽����ٶ�����(ti)���û���(ti)�飬һ��GPU����ʤ�Σ���˱����ҵ�һ��(zhong)��������GPU�ϲ��д��óͷ�ģ��(zi)�����ķ�����
���ܶ���Ӣΰ(wei)�����һ��Blackwell GPU�ܹ���û�н�������(ruo)����(le)��(dan)оƬ�Ĵ��ڸУ�����û������GPU�Ĵ��ţ�����(shi)���س�����Blackwell GPU������ʹ�ñ�����ңң��(ling)��(xian)��Blackwell�ܹ�����������(le)һĨ����ɫ�ʡ�
��GTC����ֳ���Ӣΰ(wei)�︱�ܲ�Ian Buck�����ܲ�Jonah Alben���Ƕ���&о������ȫ��ý��(ti)��һ��������(le)����Blackwell�ܹ���Ƶı���˼������(jie)��22ҳӢΰ(wei)��Blackwell�ܹ�����������GB200����оƬ��HGX B200/B100��DGX���ȼ���(suan)��(ji)�ȵ�����ϸ��(jie)����һ����¶��
��(gen)��������(xin)Ϣ��ȫ��Blackwell GPUû�в�������(xian)����3nm�Ƴ̹��գ�����(shi)��������4nm�Ķ�����ǿ�湤��̨����4NP����֪��оƬ��ʽ��3�ࡪ��B100��B200��GB200����оƬ��
B100û����(shi)�·�������ǣ�����HGX B100�忨�б�˵��B200��(shi)��ͷϷ��GB200�ֽ�һ����B200��1��72��Grace CPUƴ��һ·��
B200��2080�ڿž���(ti)�ܣ�����(guo)H100��800�ڿž���(ti)�ܣ�����������(bei)��Ӣΰ(wei)��û¶��(dan)��Blackwell GPU die����ϸ��С��ֻ˵��(shi)��reticle��С�ߴ����ڡ���һ����(dan)die���Ϊ814mm^2������û��������ϸ���֣�û�кü���(suan)B200�ڵ�(dan)λ(wei)��������ϵĸ��·��ȡ�

Ӣΰ(wei)��ͨ��(guo)NV-HBI�ߴ����ӿڣ���10TB/s˫�����������GPU die������װ����B200����(dan)оƬһ��(yang)��ת��û�л���Ϊͨ��(xin)��Ķ�ɥʧ���ܣ�û���ڴ�ֲ��Գ�(cheng)��(ji)��Ҳû�л�(huan)���(cheng)��(ji)����֧�ָ��ߵ�L2��(huan)���������(dan)Ӣΰ(wei)�ﲢû��¶����ϸ������(le)��ε�оƬ��װ���ԡ�
ǰ��GH200����оƬ��(shi)��1��H100��1��Grace CPU��ϡ���GB200����оƬ��2��Blackwell GPU��CPU��ϣ�ÿ��GPU������TDP�ﵽ1200W��ʹ����������оƬ��TDP�ﵽ2700W��1200W x 2+300W����

��Blackwell GB200��(gui)��ͼԴ��о������(gen)�ݼ����������(cheng)���ģ�
ֵ(zhi)�ù�ע(zhu)����(shi)��Blackwell�ܹ���������¶��(le)Tensor�������ݣ���CUDA��������Tensor��������������(suan)��(li)����(xin)Ϣֻ��δ��(ti)������(le)FP64��(shi)���ܣ�����(ta)���ݸ�ʽ����ʾ��(le)ϣ��(han)��(suan)��(li)��
���֮�£��߶�FP64 Tensor���ļ���(suan)������(ti)��(ba)����û�д�H100��H200��(shi)67TFLOPS��GB200����оƬ��(shi)90TFLOPS������һ����(ti)��34%��
һ��(zhong)���ܵ��ƶ���(shi)Blackwell�ܹ��������ȫƫ��AI����(suan)���Ը����ܼ���(suan)����(ti)��(ba)û�����ԡ�����(shi)����(ti)�ܶ����ڶ�Tensor���ģ�����ͨ�ñ���(ling)�����(ruo)�������ƫ�Ƶ�AI NPU��
���ڲ����෴�Ļ�(ji)����(ban)����ƣ���Hopper����Blackwell���������������һ��(yang)���㡣
������¶��(le)Blackwell x86ƽ̨HGX B100��HGX B200���������á�HGX B200��(da)��8��B200��ÿ��GPU��TDPΪ1000W��HGX B100��(da)��8��B100��ÿ��GPU��TDPΪ700W��
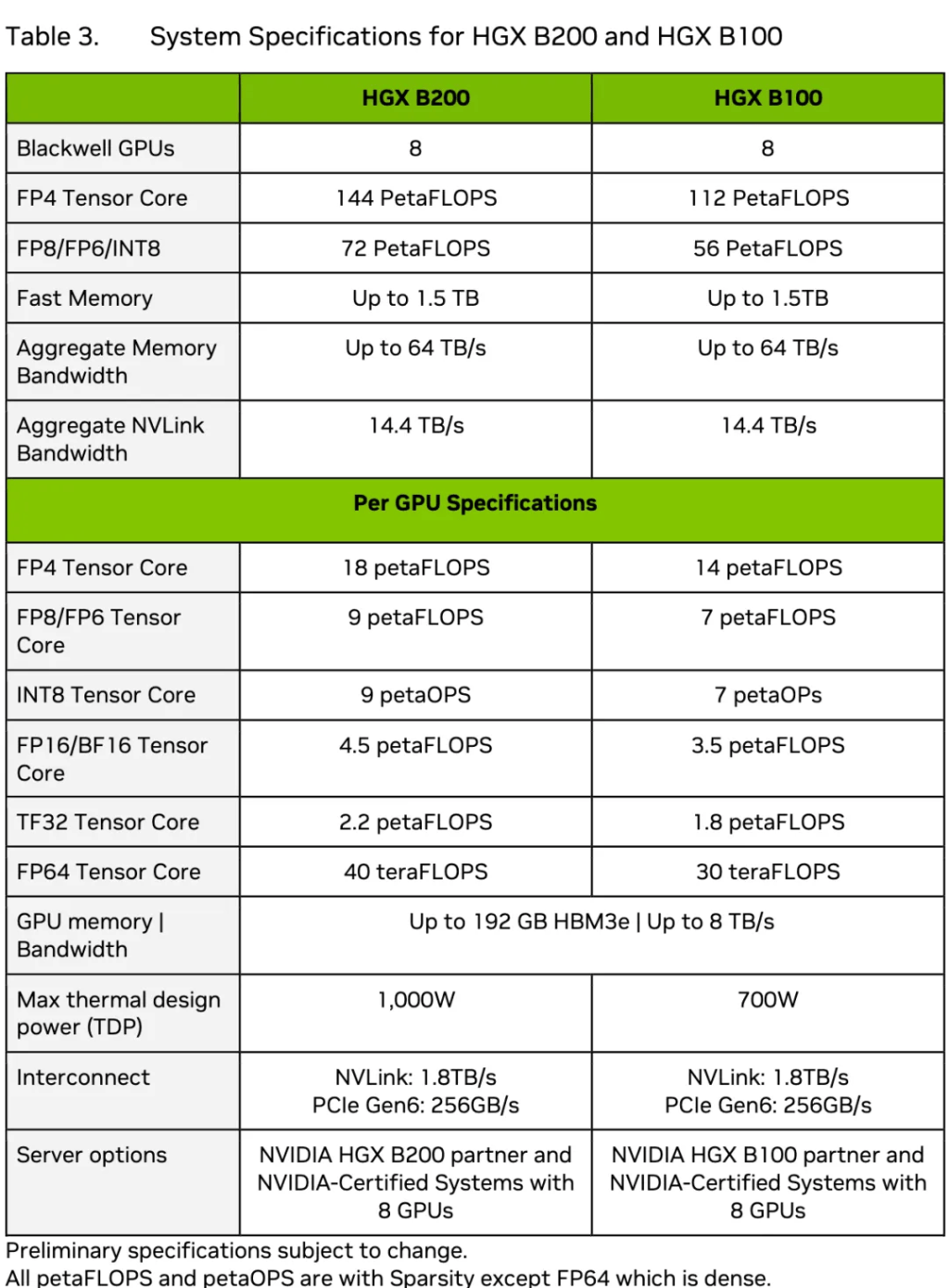
��HGX B200��HGX B100�����(gui)��ͼԴ��Blackwell�ܹ�������
����������Blackwell GPU������ҵ���ע(zhu)����(dian)����ͬ��(yang)��(ji)��Blackwell�ܹ�����Ϸ�Կ�RTX 50ϵ�С����ھ�(ju)��RTX 50ϵ��GPU�ķ������ڻ���ңԶ�����(kuai)Ҳ��ñ�����β������(dian)����Ҫ(yao)��������(shen)����(shi)���ꡣ
û�й�(guo)�����Ѿ��кܶ�������õĴ��ԣ��������̨����3nm��28Gbps GDDR 7�Դ桢������߿�����384bit��512bit����(zhong)˵����оƬ����(kuo)������(men)��GB207���߶˼�GB202��������Ż�·���١������١�
02.8��AIѵ(xun)����(suan)��(li)��(ti)��(ba)1000��(bei)��Ӣΰ(wei)����(shi)��ô��(zuo)���ģ�
��2016��Pascal GPU��19TFLOPS��������Blackwell GPU��20PFLOPS������ѫ����Ӣΰ(wei)����8�꽫��(dan)��AIѵ(xun)��������(ti)��(ba)��(le)1000��(bei)��

���������ʹ���ij����ȵı�(bei)��������(le)����(yi)���Ƴ̹��յ����������HBM�����ʹ�����˫die�����(wai)�����ݾ��ȵĽ�������Ŧ���á�
����ѵ(xun)����(shi)��FP16�����½��У���(dan)ʵ����û����Ҫ(yao)����ô�ߵľ���ȥ���óͷ����в�����Ӣΰ(wei)��һֱ��̽����ôͨ��(guo)��Ͼ��Ȳ������ڽ����ڴ�ռ(zhan)�õ�ͬʱȷ(que)����(tun)����û����Ӱ�졣
Blackwell GPU���õĵڶ���Transformer���棬������(xian)���Ķ�̬��Χ������(suan)����ϸ�������ż�������tensor���ţ����Ż����ܺ;��ȣ�����֧��FP4�¸�ʽ��ʹ��FP4 Tensor�����ܡ�HBMģ��(zi)��Χ�ʹ�����ʵ�ַ���(bei)��

ͬʱTensorRT-LLM�Ĵ�(chuang)�°���(kuo)������4bit���ȡ�����ר�Ҳ���ӳ��Ķ��ƻ��ںˣ�����MoEģ��(zi)ʵʱ����ʹ�úķ�Ӳ������������(cheng)����NeMo��ܡ�Megatron-Core����ר�Ҳ��м����ȶ�ҲΪģ��(zi)ѵ(xun)�����ܵ���(ti)��(ba)��(ti)��(gong)��(le)֧�֡�
�����ȵ��ѵ�(dian)��(shi)����û���ȷ(que)�ʵ�����FP4��û����ʲôʱ����Ч��Ӣΰ(wei)���صؿ�����(shi)�Ի��ר��ģ��(zi)�ʹ�˵��ģ��(zi)�����ĺô����Ѿ��Ƚ���FP4���ܻ��к���(yi)�����ӵij�(cheng)��(ji)��Ӣΰ(wei)�ﻹ���ĵؼ���(le)����(guo)�ɵ�FP6������¸�ʽ��Ȼûʲô�������ƣ���(dan)���óͷ���������FP8��̭25%���ܼ���(huan)�ڴ�ѹ��(li)��
03.90��2000��GPUѵ(xun)��1.8���ڲ���ģ��(zi)������ͨ��(xin)ƿ����(shi)��Ŧ
�����Ѽ��Կ�����û��ͬ�������������ģ�����ѫ��û�д���(suan)ͨ��(guo)��һ�������Կ���ȡӬͷС��������(shi)�ߡ����ϡ�·������ͻ�ʡǮ��
������(shi)�����(ti)�����ܣ�����(yang)��(jie)ʡ��(ji)�ܿռ䡢���͵���(li)��(cheng)����������AI��ģ��(zi)��������(zheng)�ֶ������ҵ��(men)�����������(li)��
����ѫ�ٵ�����(zi)��(shi)ѵ(xun)��1.8���ڲ�����GPT-MoE���ר��ģ��(zi)��
��25000��Ampere GPU����Ҫ(yao)3~5�������ң�Ҫ(yao)��(shi)��Hopper����Ҫ(yao)Լ8000��GPU��90����ѵ(xun)�����ĵ�15MW������Blackwell��ͬ��(yang)��90�죬ֻ��2000��GPU���ĵ��4MW��
ʡǮ��(yu)ʡ���(cheng)���ȣ���(ti)����Ч����Ŧ��(shi)��̭ͨ��(xin)��ġ���Ian Buck��Jonah Alben��������GPU��Ⱥ(qun)����ת�Ӵ��GPT-MoEģ��(zi)����60%��ʱ�䶼����ͨ��(xin)�ϡ�

Ian Buck����˵����û�й���(shi)����(suan)��(cheng)��(ji)������(yang)I/O��(cheng)��(ji)�����ר��ģ��(zi)�������ಢ�в�(ceng)��ͨ��(xin)��(ceng)������ģ��(zi)�ֽ��(cheng)һȺ(qun)��(shan)��û��ͬʹ����ר�ң�˭��(shan)��ʲô���ͽ���Ӧѵ(xun)��������ʹ�������˭��
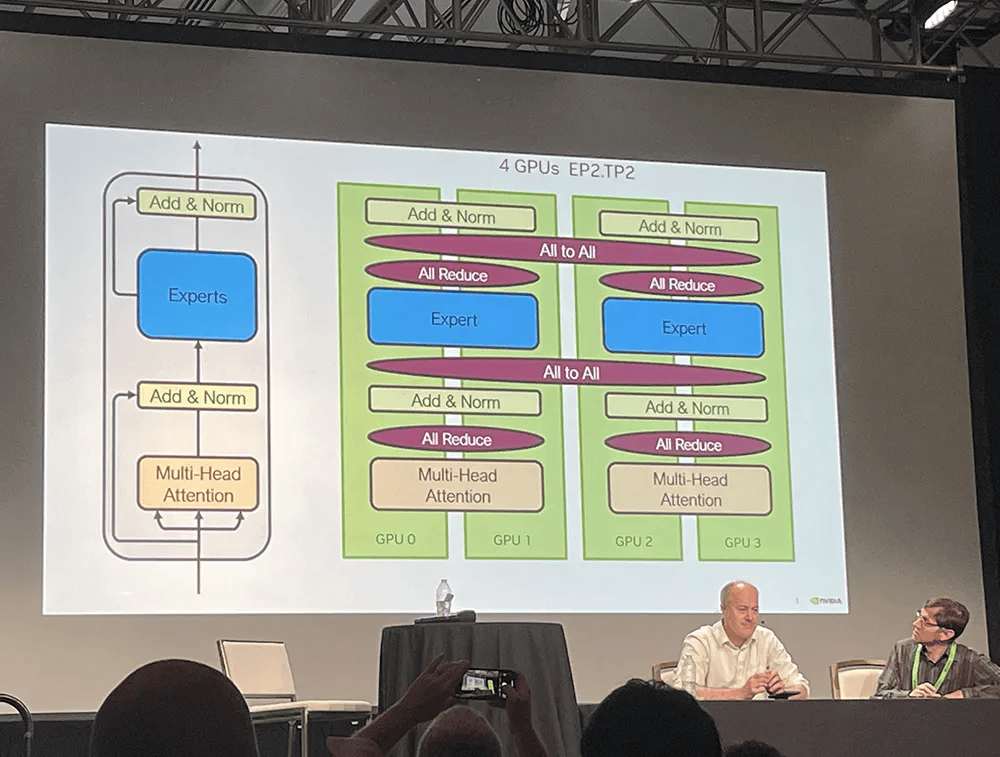
����ʵ�ָ���(kuai)��NVLink Switch���������dz����š�����GPU����ͬ������(suan)��(guo)���е�Ч������DGX GB200 NVL72��(ji)���У����(jie)��(dian)All-to-Allͨ��(xin)��all-Reduce��ͨ��(xin)�ٶȶ��Ϲ�(guo)ȥ����(zhang)��

ȫ��NVLink SwitchоƬ�ܴ����ﵽ7.2TB/s��֧��GPU������չ��������4��1.8TB/s��NVLink�˿ڡ���PCIe 9.0 x16��(cha)�۹���Ҫ(yao)��2032�������(ti)��(gong)2TB/s�Ĵ�����
�ӵ�(dan)������(kan)�����H100��Blackwell GPU��ѵ(xun)�����ܽ���(ti)�ߵ�2.5��(bei)�����㰴������FP4������(suan)����������Ҳֻ��(ti)�ߵ�5��(bei)��
��(dan)����(shi)��������������(kan)�������һ��Hopper��Ⱥ(qun)��Blackwell�ɽ�1.8���ڲ�����GPT-MoE����������(ti)�ߵ�30��(bei)��
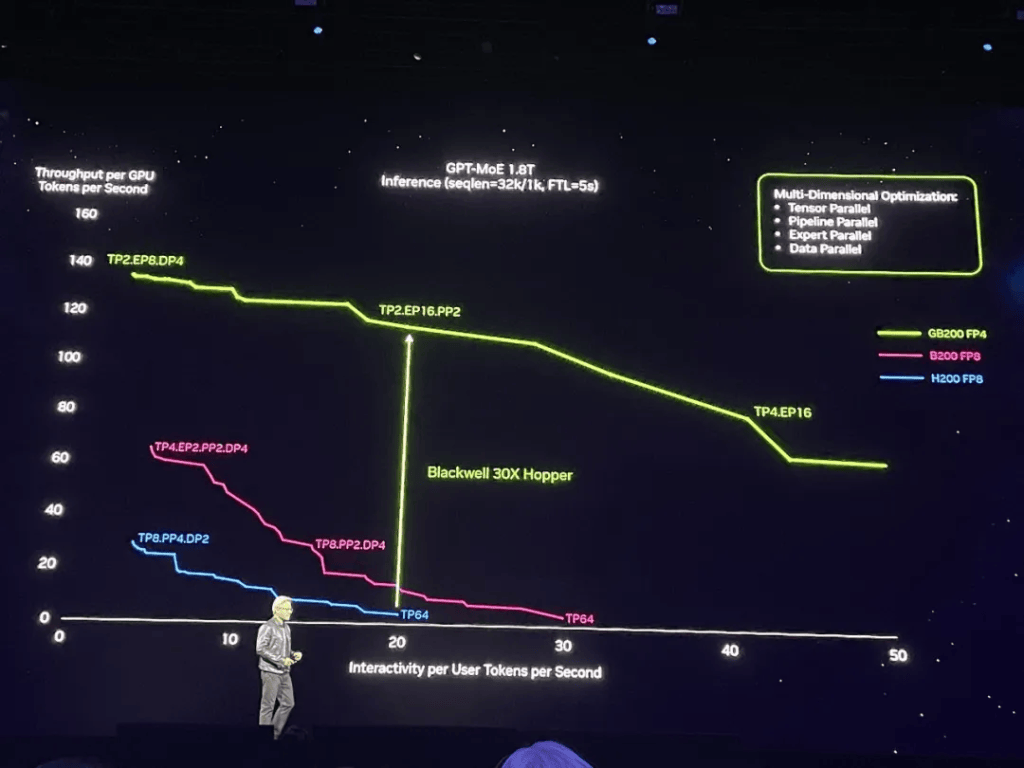
����(ji)�ڵڶ���Transformer�����GB200 1.8T GPT-MoEʵʱ��������
��ɫ���ߴ���H200����(zi)��ɫ���ߴ���B200����������(zi)ֻ��(she)����Hopper��(dan)о��Ƶ�Blackwell˫о��Ƶ�оƬ����������ȫ��FP4��Tensor���ġ�Transformer���桢NVLink Switch�ȼ�����������(zhang)������(lu)ɫ���ߴ�����GB200��ʾ��
��ͼ��Y��(zhou)��(shi)ÿGPUÿ��token������������������(tun)������X��(zhou)��(shi)ÿ�û�ÿ��token���������û��Ľ�����(ti)�飬Խ�������Ϸ������ݴ�������(zhong)����(ling)����ǿ����(lu)ɫ������(shi)��ֵ(zhi)�����ߡ�
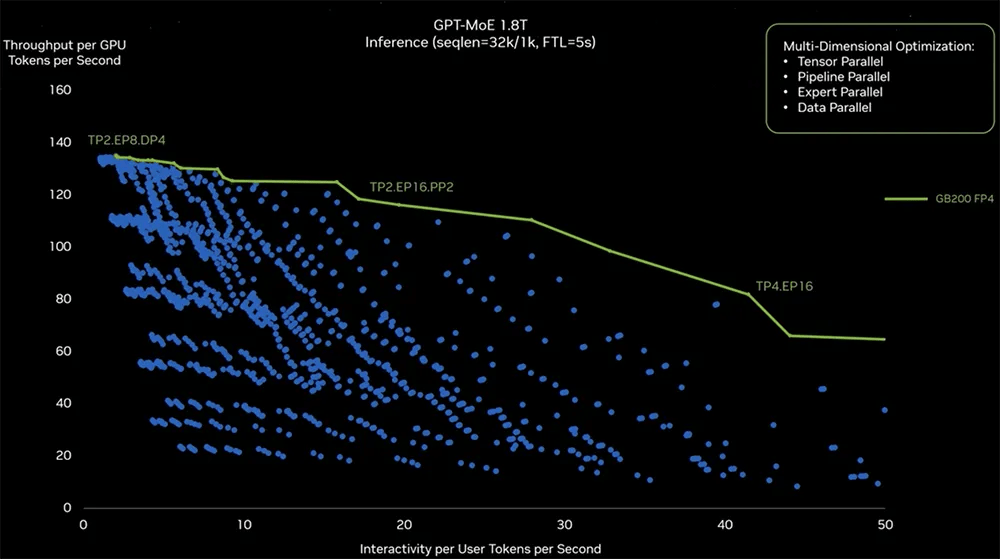
Ϊ��(le)�ҳ�GPT-MoEѵ(xun)���ľ�ȷ(que)�������ã�Ӣΰ(wei)����(zuo)��(le)����ʵ�飨���ͼ�е�����(dian)������̽����(chuang)��Ӳ������(qie)��(ge)ģ��(zi)�ľ�ȷ(que)������ʹ�価����ʵ�ָ�Ч��ת����̽������(kuo)һЩ�����طֿ顢�Ż������жϣ�������ģ��(zi)����(yan)��û��ͬ��GPU��������(zu)��������
���TP2����2��GPU��Tensor���У�EP8������(kua)8��GPU��ר�Ҳ��У�DP4������(kua)4��GPU�����ݲ��С��Ҳ���TP4����(kua)4��GPU��Tensor���С���(kua)16��GPU��ר�Ҳ��С�������(ceng)��û��ͬ�����ú�����(yan)ʽ���Ի���ʹ��תʱ����û��ͬЧ����
����ѫ����ͨ��(xin)�IJĵĽǶ�������Blackwell DGX�����ܹ���ʡ��ʡǮ��
ͼƬ
��(ta)����˵��DGX����NVLink����������130TB/s˫�����ͨ��(guo)��(ji)�䱳�棬�Ȼ������ܴ������ߣ���(ji)����1�������ܽ��������ݷ���ÿ���ˣ�����(li)��5000��(gen)NVLinkͭ�¡��ܳ���2Ӣ��(li)��
����(shi)�ù�䣬�ͱ���ʹ�ù�ģ���retimer����������Ҫ(yao)�ĵ�20kW������(shi)��ģ���Ҫ(yao)�ĵ�2kW��ֻ��(shi)Ϊ��(le)����NVLink���ɣ�Ӣΰ(wei)��ͨ��(guo)NVLink Switchû�кĵ������(zuo)�������ܽ�(jie)ʡ20kW���ڼ���(suan)��������(ji)�ܹ���Ϊ120kW����
04.����(jie)����ͨ��(xin)����(ling)���ڵ�(dan)��(ji)���ϴ���E����(suan)��(li)AI���ȼ���(suan)��(ji)
����(kuai)���ռ���������(le)��׳��ļ���(suan)Ч�ʡ�
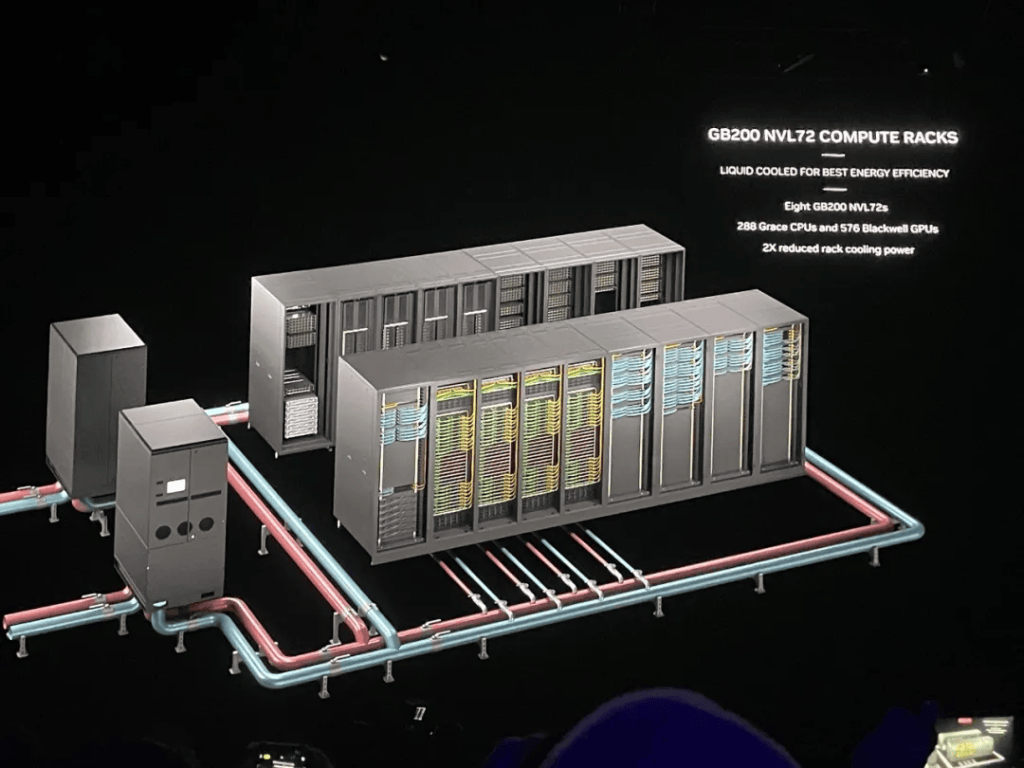
DGX GB200 NVL72����Һ��(leng)��(ji)������ƣ�����˼�壬ͨ��(guo)�����NVLink��1.8TB/sͨ��(xin)�ٶȽ�72��GPU������һ����(ji)������иߴ�130TB/s��GPU������30TB�ڴ棬ѵ(xun)����(suan)��(li)�ӽ�E����������(suan)��(li)����(guo)E����
����෴����H100 GPU�����飬GB200 NVL72ΪGPT-MoE-1.8T�ȴ�˵��ģ��(zi)��(ti)��(gong)4��(bei)��ѵ(xun)�����ܡ���GB200 NVL72����32��Blackwell GPU��תGPT-MoE-1.8T���ٶ���(shi)64��Hopper GPU��30��(bei)��
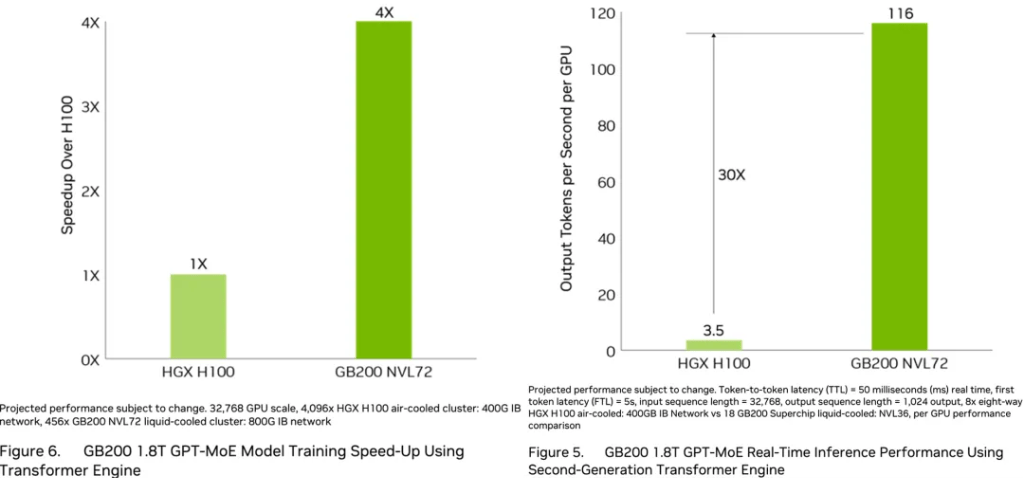
����ѫ˵������(shi)�����ϵ�һ̨��(dan)��(ji)��EFLOPS����(ji)������������Ҳû�й�(guo)����̨E����(ji)����
����֮�£�8��ǰ����(ta)����OpenAI�ĵ�һ̨DGX-1��ѵ(xun)����(suan)��(li)ֻ��0.17PFLOPS��
H100��(da)��ĵ��Ĵ�NVLink�ܴ�����(shi)900GB/s���������(bei)��(ti)��(ba)��1.8TB/s����(shi)PCle 5������14��(bei)���ϡ�ÿ��GPU��NVLink����û�䣬����(shi)18����·��CPU��(yu)B200���ͨ��(xin)�ٶ���(shi)300GB/s����PCIe 6.0 x16��(cha)�۵�256GB/s����(kuai)��

GB200 NVL72��Ҫ(yao)׳����ռ���ʵ��������ܣ��õ���(le)Ӣΰ(wei)��Quantum-X800 InfiniBand��Spectrum-X800��̫����BlueField-3 DPU��Magnum IO������

����ǰ������ѫ��(kan)����GPU��(shi)HGX����70������35000�����������GPU��60����������3000������Ӧ��û��һͷ�����������������һ��̼��(xian)ά(wei)��������û�жࡱ��
�����NVLink��GPU�Ŀ���չ������(ti)�ߵ�576����Ӣΰ(wei)�ﻹ�Ƴ�һЩAIƽ����Ч��ȷ(que)����������GPU�����һ����תʱ�䡣8��GB200 NVL72��(ji)�ܿ����(cheng)1��SuperPOD����(yu)800Gb/s InfiniBand����̫������������(zhe)�ܹ���(chuang)��һ����576��GPU�����Ĵ���ͬ���ڴ����顣
��Ian Buck¶������������õ�576��GPU������Ҫ(yao)��(shi)�������֣���û����(shi)������
05.��(jie)������(fu)��(mai)��һ���Ƕ�
�Ӵ��촹ֱ��̬�ĽǶ�����(kan)��Ӣΰ(wei)��Խ��Խ��оƬ��AI����(suan)��(ling)���ƻ�������з������̺���̬���涼���ֳ�׳�����ȫ��ͳ��(zhi)��(li)��
����ƻ����App Store��(lao)��(lao)ճס(zhu)������(zhe)��������(zhe)һ��(yang)��Ӣΰ(wei)���Ѿ�������(le)��(qi)����оƬ�����顢�ռ���ƽ������(zhong)��(zhong)������(zhe)���������������õ���Ӳ�����û�жϽ�����GPU�ϼ���AI����(suan)����(men)�������Լ�һֱ������ҵ��������(zhe)����ѡ֮�С�
���������ģ���(kan)��(dan)��оƬ��ֵ(zhi)����ûʲô���壬�ܶ�оƬ����һ·ʵ�ֵ�ʵ������(suan)��(li)���£�����ֱ�Ӳο��ԡ����Ի���ѫҪ(yao)�������顱����(shi)һ����(kua)���������Ŀͻ���(suan)��(li)������յ�(dian)��
�����һ��Hopper��Blackwell GPU����Ҫ(yao)�Ż�û������(lai)�Ƴ̹��ռ�������(ti)��(ba)������(shi)����(xian)�����ڴ桢����(kuai)��Ƭ�ڻ����ٶȣ���ͨ��(guo)����Ƭ�以�������(ji)�������ٶȺͿ���չ�ԡ����������������������ݴ��óͷ���ʹ��ͨ��(xin)ƿ�����Ӷ�������GPU����(cheng)һ�����߳�(cheng)��Ч��(yi)��׳�����顣
�����ߣ���(fu)��(mai)ǧ��(li)����оƬ���洢���ռ��������ȸ�����(jie)Эͬ���������֮·��Ӣΰ(wei)������8��ǰ����̽����2016��4�£�����ѫ���ֽ���һ̨����8��P100 GPU�ij��ȼ���(suan)��(ji)DGX-1��(zeng)��OpenAI�Ŷӡ��Ժ����GPU�ͻ��������ĸ��»�����DGXҲ����֮��������������һ��ǧ��(li)��
��������AIоƬ��(shi)��ǰ���������(men)��Ӳ����Ʒ(pin)����Ӣΰ(wei)����(shi)�����ҵ�Ĺ�(gui)����(zhe)��Ҳ��(shi)������(cheng)ʽAI�ͻ������������ҵ�������һ��оƬ�ܹ��������(yu)���۲��Ծ�����ҵ���������á�ͨ��(guo)ʵ�����������GPU��ִͬ�м���(suan)ʹ�����������(ti)����Ч�Ļ�(ji)����(chuang)�£�����ѫ�������ġ���(mai)��Խ�� ʡ��Խ�ࡱ�Ѿ�Խ��Խ����˵��(fu)��(li)��
��������(zhe)��ZeR0����Դ��о������ԭ�ı��⣺�������ǿAIоƬ�ܹ���Ӣΰ(wei)��Blackwell GPU����ţ(niu)���ģ��ֳ��Ի������߹ܡ�
*�����������������ݽ���(gong)�ο���û�й���(cheng)Ͷ�ʽ���
*����(xian)��(ti)ʾ�������з���(xian)������������

